
Ven! No temas! Inteligencia Artificial para todos!
Ven! No temas! Inteligencia Artificial para todos!
Un enfoque simple y claro para que cualquiera entienda la inteligencia artificial
ChatGPT, el nombre que pronuncian todas las bocas! Desde estudiantes de secundaria y maestros preocupados, hasta CEO's de empresas trasnacionales en ponencias de negocios.
Pero, ¿qué es en realidad un Large Language Model (LLM) como ChatGPT? La respuesta corta es: una aproximación estadística al lenguaje. Y como toda definición corta, es precisa pero poco útil.
A través de este artículo, voy a explicar con términos simples y sin tecnicismos cómo funcionan los LLMs. Mi objetivo es que cualquier persona, sin importar su formación técnica, pueda entender los mecanismos detrás de estas tecnologías que están transformando nuestro mundo.
Introducción
Imaginemos que tenemos un automóvil mágico. Este auto puede llevarnos a cualquier lugar que le pidamos, sin importar qué tan específico o complejo sea el destino. Solo necesitamos decirle dónde queremos ir y él nos lleva ahí.
Pero hay un detalle: no sabemos exactamente cómo funciona por dentro. Sabemos que tiene un motor, ruedas, y que consume combustible, pero los mecanismos internos son un misterio para nosotros.
Los Large Language Models son como ese automóvil mágico, pero para el lenguaje. Les decimos lo que queremos (en forma de texto) y ellos nos responden con texto que parece haber sido escrito por un humano. Pero al igual que con el auto mágico, entender cómo funcionan por dentro es más complejo.
En este artículo, vamos a "abrir el capó" de este automóvil mágico del lenguaje para entender qué hay adentro.
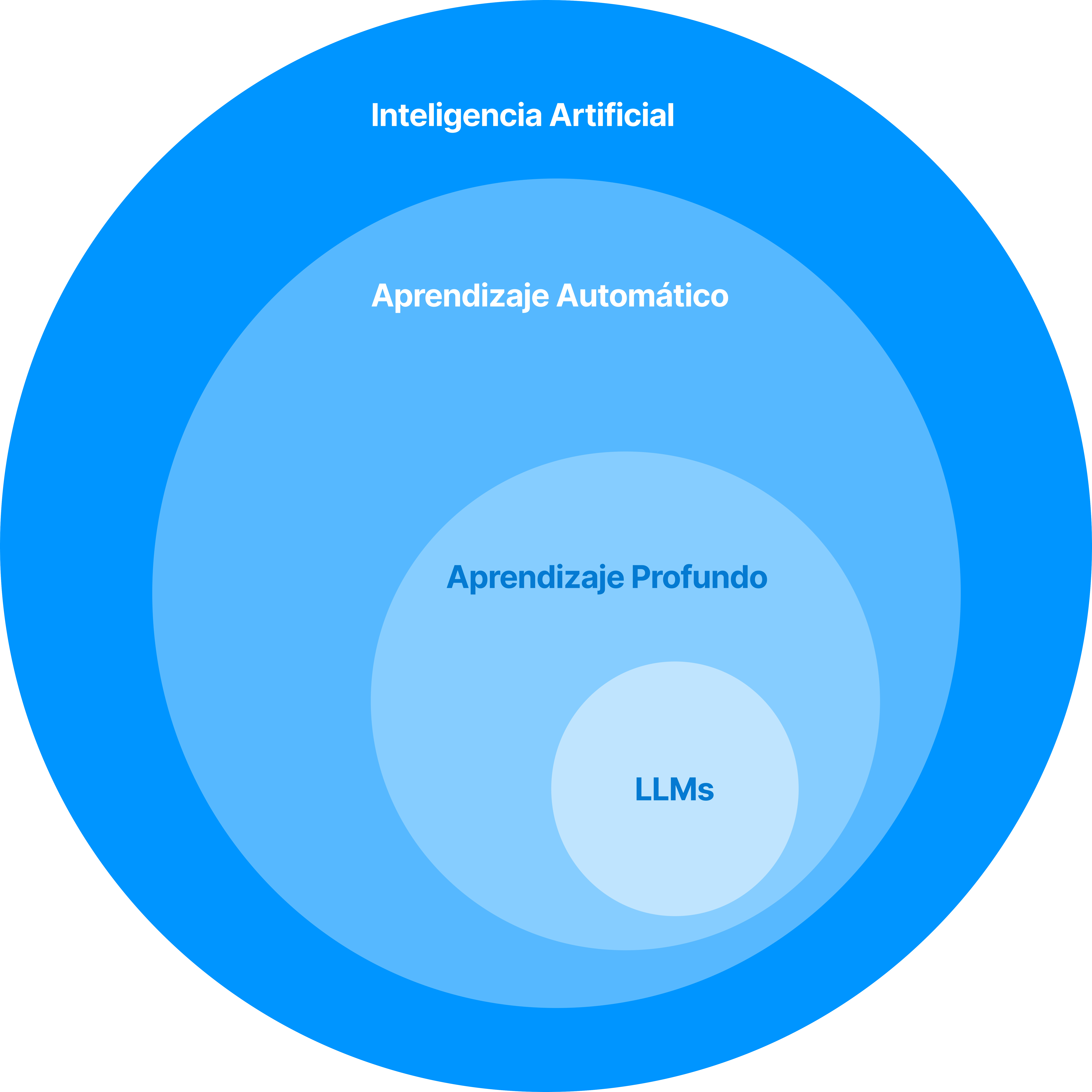
Las 4 Capas para entender un LLM
Para hacer esto más digerible, voy a dividir la explicación en 4 capas:
1. Interfaz de Usuario (Lo que vemos)
Esta es la capa más familiar para todos nosotros. Es la pantalla donde escribimos nuestras preguntas y recibimos respuestas. Ejemplos:
- El chat de ChatGPT
- Gemini de Google
- Claude de Anthropic
- Copilot de Microsoft
2. Aplicación (El intermediario)
Esta capa toma lo que escribimos, lo procesa y lo prepara para enviarlo al modelo. También toma la respuesta del modelo y la presenta de manera amigable. Piénsalo como un traductor e intérprete.
3. Modelo (El cerebro)
Aquí es donde ocurre la "magia". El modelo recibe texto y produce texto. Esta es la parte más compleja y de la que hablaremos más en este artículo.
4. Infraestructura (Los músculos)
Son los servidores, las computadoras y la energía necesaria para que todo funcione. Sin esta capa, las otras tres no podrían existir.
Ahora que tenemos esta vista general, profundicemos en cada capa.
Capa 1: Interfaz de Usuario
Esta es la parte que todos conocemos. Es donde interactuamos con el sistema. Aquí algunos ejemplos:
ChatGPT:
- Interfaz web limpia y simple
- Conversación en formato de chat
- Opciones para diferentes modelos (GPT-3.5, GPT-4, etc.)
Google Gemini:
- Integrado con la búsqueda de Google
- Puede generar imágenes además de texto
- Interfaz familiar para usuarios de Google
Claude:
- Enfoque en conversaciones largas y detalladas
- Excelente para análisis de documentos
- Interfaz minimalista
La interfaz es crucial porque determina cómo experimentamos la inteligencia artificial. Una buena interfaz hace que la tecnología compleja sea accesible; una mala interfaz puede hacer que hasta la mejor tecnología sea inutilizable.
Capa 2: Aplicación
Esta capa es como el director de orquesta. Coordina todo lo que sucede entre la interfaz y el modelo. Sus funciones principales incluyen:
Procesamiento de entrada
- Toma lo que escribimos y lo convierte en un formato que el modelo puede entender
- Añade contexto adicional si es necesario
- Aplica filtros de seguridad
Gestión de conversación
- Mantiene el historial de la conversación
- Decide qué información pasarle al modelo
- Gestiona el contexto de múltiples intercambios
Procesamiento de salida
- Toma la respuesta "cruda" del modelo
- La formatea para presentación
- Aplica filtros de seguridad adicionales
Ejemplo práctico:
Cuando escribes "¿Cuál es la capital de Francia?" en ChatGPT:
- La aplicación toma tu pregunta
- Añade contexto: "Eres un asistente útil. Responde de manera concisa y precisa."
- Envía todo esto al modelo
- El modelo responde: "La capital de Francia es París."
- La aplicación presenta esta respuesta en la interfaz
Capa 3: Modelo (El Cerebro)
Esta es la parte más fascinante y compleja. El modelo es donde realmente "sucede" la inteligencia artificial. Pero, ¿qué es exactamente un modelo de lenguaje?
¿Qué es un modelo de lenguaje?
Un modelo de lenguaje es, en esencia, un sistema que predice palabras. Dado un texto, puede predecir qué palabra (o palabras) es más probable que siga.
Por ejemplo, si le das el texto:
"El cielo es de color..."
Un buen modelo de lenguaje predecirá que "azul" es la palabra más probable que sigue.
¿Cómo aprende a predecir?
Aquí es donde entra el aprendizaje de máquina (machine learning). El proceso es sorprendentemente similar a cómo aprenden los humanos:
1. Exposición masiva a texto
El modelo "lee" cantidades enormes de texto de internet:
- Artículos de Wikipedia
- Libros digitalizados
- Sitios web
- Foros de discusión
- Artículos académicos
2. Práctica constante de predicción
Durante el entrenamiento, el modelo:
- Lee una oración incompleta
- Intenta predecir la siguiente palabra
- Compara su predicción con la palabra real
- Ajusta sus "parámetros internos" para mejorar
3. Repetición masiva
Este proceso se repite billones de veces con diferentes textos hasta que el modelo se vuelve muy bueno prediciendo palabras en contexto.
Un ejemplo simplificado
Imaginemos que estamos entrenando un modelo con estas oraciones:
- "Los gatos son animales domésticos"
- "Los perros son animales domésticos"
- "Los peces son animales acuáticos"
Después del entrenamiento, si le damos "Los hamsters son animales...", el modelo podría predecir "domésticos" porque ha aprendido el patrón.
De predicción de palabras a conversación
Pero, ¿cómo pasa el modelo de simplemente predecir palabras a mantener conversaciones coherentes?
La respuesta está en dos conceptos clave:
1. Contexto extenso
Los modelos modernos pueden "recordar" y procesar textos muy largos (hasta 200,000 palabras o más). Esto les permite mantener el hilo de conversaciones complejas.
2. Entrenamiento en conversaciones
Además de leer texto general, los modelos son entrenados específicamente en:
- Conversaciones humanas
- Preguntas y respuestas
- Instrucciones y tareas
Parámetros: Los "recuerdos" del modelo
Cuando hablamos de que GPT-4 tiene "1.8 billones de parámetros", ¿qué significa esto?
Los parámetros son como los "recuerdos" o "conocimientos" que el modelo ha aprendido durante su entrenamiento. Cada parámetro es un número que influye en cómo el modelo procesa y responde a diferentes tipos de texto.
Más parámetros generalmente significan:
- Mayor capacidad de memoria
- Mejor comprensión de contextos complejos
- Respuestas más sofisticadas
- Pero también mayor costo computacional
Capa 4: Infraestructura
Esta es la base física que hace posible todo lo anterior. Incluye:
Hardware especializado
- GPUs (Unidades de Procesamiento Gráfico): Diseñadas originalmente para gráficos, resultan ser perfectas para los cálculos masivos que requieren los LLMs
- TPUs (Unidades de Procesamiento Tensorial): Chips especializados diseñados específicamente para inteligencia artificial
- Servidores: Computadoras potentes que hospedan los modelos
Datos y almacenamiento
- Centros de datos: Enormes instalaciones que albergan miles de servidores
- Sistemas de almacenamiento: Para guardar los modelos entrenados y los datos de usuario
- Redes de alta velocidad: Para transferir información rápidamente
Costos operativos
Ejecutar un LLM como ChatGPT es extremadamente costoso:
- Electricidad: Los centros de datos consumen enormes cantidades de energía
- Mantenimiento: Hardware especializado que requiere cuidado constante
- Personal: Ingenieros y técnicos especializados
Se estima que cada conversación con ChatGPT cuesta a OpenAI entre $0.01 y $0.10, dependiendo de la longitud y complejidad.
Aprendizaje de Máquina: La magia detrás del modelo
Para entender realmente cómo funcionan los LLMs, necesitamos entender los fundamentos del aprendizaje de máquina (machine learning).
¿Qué es el aprendizaje de máquina?
Es una forma de enseñar a las computadoras sin programarlas explícitamente. En lugar de escribir instrucciones paso a paso, les mostramos ejemplos y dejamos que encuentren patrones por sí mismas.
Analogía: Aprender a reconocer gatos
Imaginemos que queremos enseñar a una computadora a reconocer gatos:
Método tradicional (programación):
SI tiene_orejas_puntiagudas Y tiene_bigotes Y dice_miau:
ENTONCES es_un_gato = VERDADERO
Problema: ¿Cómo codificamos todas las variaciones posibles de gatos?
Método de aprendizaje de máquina:
- Mostramos 10,000 fotos etiquetadas: "gato" o "no gato"
- El algoritmo encuentra patrones en los píxeles
- Después de entrenar, puede clasificar fotos nuevas
Aplicado a lenguaje
Los LLMs aplican este mismo principio al lenguaje:
- Datos de entrenamiento: Billones de palabras de texto
- Tarea: Predecir la siguiente palabra en una secuencia
- Resultado: Un modelo que "entiende" patrones del lenguaje
Los tres tipos de aprendizaje
1. Aprendizaje supervisado
- Ejemplo: Traducción automática
- Proceso: Mostramos pares de oraciones (español-inglés)
- Resultado: El modelo aprende a traducir
2. Aprendizaje no supervisado
- Ejemplo: Análisis de sentimientos
- Proceso: Damos textos sin etiquetas
- Resultado: El modelo encuentra patrones (positivo/negativo)
3. Aprendizaje por refuerzo
- Ejemplo: Juegos de ajedrez
- Proceso: El modelo juega miles de partidas
- Resultado: Aprende estrategias ganadoras
Los LLMs combinan principalmente los tipos 1 y 3.
Deep Learning: Las redes neuronales
Los LLMs utilizan una técnica específica de aprendizaje de máquina llamada deep learning (aprendizaje profundo), que se basa en redes neuronales artificiales.
¿Qué son las redes neuronales?
Son sistemas inspirados (muy vagamente) en cómo funciona el cerebro humano. Consisten en:
Neuronas artificiales
Unidades de procesamiento simple que:
- Reciben información
- La procesan
- Producen una salida
Capas
Las neuronas se organizan en capas:
- Capa de entrada: Recibe los datos iniciales
- Capas ocultas: Procesan la información
- Capa de salida: Produce el resultado final
Conexiones
Las neuronas están conectadas entre sí, y cada conexión tiene un "peso" que determina su importancia.
Ejemplo simplificado: Reconocimiento de dígitos
Imaginemos una red neuronal que reconoce números escritos a mano:
- Entrada: Una imagen de 28x28 píxeles (784 números)
- Capas ocultas: Varias capas que identifican patrones (líneas, curvas, formas)
- Salida: 10 números indicando la probabilidad de cada dígito (0-9)
¿Por qué "profundo"?
"Deep" se refiere a que tiene muchas capas (a veces cientos). Cada capa aprende patrones más complejos:
- Capa 1: Detecta líneas y bordes simples
- Capa 2: Combina líneas en formas básicas
- Capa 3: Reconoce partes de objetos
- Capa 4: Identifica objetos completos
Transformers: La arquitectura detrás de los LLMs
Los LLMs modernos utilizan una arquitectura específica llamada Transformer, introducida en 2017 en un paper titulado "Attention Is All You Need".
¿Qué hace especial a los Transformers?
1. Atención (Attention)
La gran innovación es el mecanismo de "atención", que permite al modelo enfocarse en las partes más relevantes del texto de entrada.
Ejemplo: En la oración "La biblioteca está cerrada porque es domingo", cuando el modelo procesa "cerrada", presta más atención a "biblioteca" y "domingo" que a otras palabras.
2. Procesamiento paralelo
A diferencia de arquitecturas anteriores que procesaban palabras una por una, los Transformers pueden procesar todas las palabras al mismo tiempo. Esto los hace mucho más rápidos de entrenar.
3. Escalabilidad
Los Transformers funcionan mejor cuando son más grandes. Esto llevó a la carrera por crear modelos cada vez más masivos.
Componentes clave de un Transformer
Encoder y Decoder
- Encoder: "Lee" y entiende el texto de entrada
- Decoder: Genera el texto de salida palabra por palabra
Self-Attention
Cada palabra puede "prestar atención" a todas las demás palabras en la secuencia, permitiendo capturar relaciones complejas.
Positionencoding
Como el modelo procesa todas las palabras simultáneamente, necesita una forma de saber el orden. La codificación posicional le dice dónde está cada palabra en la secuencia.
El proceso de entrenamiento
Entrenar un LLM es un proceso masivo y costoso. Veamos cómo sucede:
Fase 1: Pre-entrenamiento
Recolección de datos
- Fuentes: Internet, libros, artículos académicos, código fuente
- Cantidad: Terabytes de texto (billones de palabras)
- Limpieza: Filtrar contenido inapropiado, duplicados, baja calidad
Tokenización
El texto se divide en "tokens" (unidades más pequeñas):
- Palabras completas: "perro"
- Partes de palabras: "anti-" + "bacterial"
- Caracteres especiales: puntuación, números
Entrenamiento autoregresivo
El modelo aprende a predecir la siguiente palabra:
Entrada: "El gato está"
Target: "durmiendo"
Recursos necesarios
- Tiempo: Semanas o meses
- Hardware: Miles de GPUs/TPUs
- Costo: Millones de dólares
- Energía: Equivalente al consumo de una ciudad pequeña
Fase 2: Fine-tuning (Ajuste fino)
Una vez que el modelo base está entrenado, se especializa para tareas específicas:
Instruction Tuning
Se entrena con ejemplos de instrucciones y respuestas:
Instrucción: "Explica qué es la fotosíntesis"
Respuesta: "La fotosíntesis es el proceso por el cual..."
RLHF (Reinforcement Learning from Human Feedback)
Humanos califican las respuestas del modelo:
- Buena respuesta: +1 punto
- Respuesta regular: 0 puntos
- Mala respuesta: -1 punto
El modelo aprende a generar respuestas que los humanos prefieren.
Capacidades emergentes
Una de las cosas más sorprendentes de los LLMs es que desarrollan capacidades que no fueron explícitamente programadas. Estas se llaman capacidades emergentes.
Ejemplos de capacidades emergentes
1. Razonamiento lógico
Aunque fueron entrenados solo para predecir texto, pueden resolver problemas de lógica:
Pregunta: "Si todos los gatos son mamíferos y Fluffy es un gato, ¿qué es Fluffy?"
Respuesta: "Fluffy es un mamífero."
2. Aritmética
Pueden hacer cálculos matemáticos sin haber sido programados específicamente para ello.
3. Programación
Pueden escribir código en múltiples lenguajes de programación.
4. Traducción
Pueden traducir entre idiomas, incluso idiomas que raramente aparecían juntos en los datos de entrenamiento.
5. Creatividad
Pueden escribir poesía, cuentos, y otros contenidos creativos.
¿Por qué emergen estas capacidades?
Esto sigue siendo un área activa de investigación, pero las teorías principales incluyen:
1. Escala
Cuando los modelos alcanzan cierto tamaño, parecen "despertar" nuevas habilidades.
2. Representaciones internas ricas
Al procesar tanto texto, desarrollan representaciones internas complejas del mundo.
3. Transferencia de patrones
Patrones aprendidos en una tarea se transfieren a otras tareas relacionadas.
Limitaciones y desafíos
A pesar de sus capacidades impresionantes, los LLMs tienen limitaciones importantes:
1. Alucinaciones
Los modelos pueden generar información que suena convincente pero es completamente falsa.
Ejemplo:
Pregunta: "¿Cuándo se inventó el teléfono cuántico?"
Respuesta incorrecta: "El teléfono cuántico fue inventado en 1987 por Dr. Smith..."
2. Falta de conocimiento actualizado
Los modelos solo saben hasta su fecha de entrenamiento.
3. Sesgos
Reflejan los sesgos presentes en sus datos de entrenamiento:
- Sesgos culturales
- Sesgos de género
- Sesgos raciales
4. Falta de razonamiento causal
No entienden realmente causa y efecto, solo correlaciones estadísticas.
5. Consumo energético
Entrenar y ejecutar LLMs consume enormes cantidades de energía.
6. Costos
Desarrollar y mantener LLMs es extremadamente costoso.
El futuro de los LLMs
Los LLMs están evolucionando rápidamente. Algunas tendencias importantes:
1. Modelos más grandes y eficientes
- Más parámetros pero mejor optimizados
- Mejor rendimiento con menos recursos
2. Especialización
- Modelos especializados para medicina, ciencia, arte
- Modelos optimizados para tareas específicas
3. Multimodalidad
- Integración de texto, imagen, audio, video
- Modelos que pueden "ver" y "escuchar"
4. Agentes autónomos
- LLMs que pueden usar herramientas
- Sistemas que pueden completar tareas complejas de forma autónoma
5. Democratización
- Modelos más pequeños que pueden ejecutarse en dispositivos personales
- Herramientas más accesibles para crear aplicaciones de IA
Herramientas prácticas para explorar LLMs
Si quieres experimentar con LLMs, aquí tienes algunas opciones:
Para usuarios generales:
- ChatGPT: chat.openai.com
- Claude: claude.ai
- Gemini: gemini.google.com
- Copilot: copilot.microsoft.com
Para desarrolladores:
- APIs: OpenAI API, Anthropic API, Google AI Studio
- Modelos locales: Ollama, LM Studio
- Plataformas de desarrollo: Hugging Face, Replicate
Para investigadores:
- Datasets: The Pile, Common Crawl, OpenWebText
- Frameworks: PyTorch, TensorFlow, JAX
- Papers: ArXiv, Google Scholar, Papers With Code
Casos de uso prácticos
Los LLMs tienen aplicaciones en prácticamente todos los campos:
Educación
- Tutores personalizados
- Generación de contenido educativo
- Evaluación automática
Medicina
- Asistentes para diagnóstico
- Análisis de literatura médica
- Educación de pacientes
Negocios
- Atención al cliente automatizada
- Análisis de documentos
- Generación de reportes
Creatividad
- Escritura asistida
- Generación de ideas
- Colaboración artística
Programación
- Generación de código
- Debugging asistido
- Documentación automática
Consideraciones éticas
El desarrollo de LLMs plantea importantes cuestiones éticas:
1. Desinformación
- ¿Cómo prevenir la generación de información falsa?
- ¿Quién es responsable del contenido generado?
2. Trabajo y empleo
- ¿Qué trabajos serán reemplazados?
- ¿Cómo preparar a la sociedad para estos cambios?
3. Privacidad
- ¿Qué datos personales usan estos modelos?
- ¿Cómo proteger la información sensible?
4. Concentración de poder
- ¿Es problemático que pocas empresas controlen esta tecnología?
- ¿Cómo democratizar el acceso?
5. Impacto ambiental
- ¿Vale la pena el costo energético?
- ¿Cómo hacer la IA más sostenible?
Conclusión: Desmitificando la "magia"
Después de este recorrido, espero que los LLMs ya no parezcan tan misteriosos. Al final del día, son sistemas estadísticos muy sofisticados que han aprendido patrones del lenguaje humano a partir de enormes cantidades de texto.
Lo que son:
- Predictores de texto extraordinariamente buenos
- Sistemas que han aprendido patrones complejos del lenguaje
- Herramientas poderosas para aumentar la productividad humana
Lo que NO son:
- Consciencias artificiales
- Sistemas que "entienden" en el sentido humano
- Reemplazos completos para el juicio humano
El mensaje principal:
Los LLMs son herramientas increíblemente poderosas que pueden transformar cómo trabajamos, aprendemos y creamos. Pero como toda herramienta poderosa, necesitamos entenderlas bien para usarlas de manera efectiva y responsable.
La clave está en desmitificar sin minimizar. No son magia, pero sí son extraordinarios. No son perfectos, pero sí son útiles. No van a resolver todos nuestros problemas, pero sí van a cambiar la forma en que abordamos muchos de ellos.
El futuro será construido por quienes entienden estas herramientas y saben cómo aplicarlas de manera inteligente y ética. Espero que este artículo te haya dado una base sólida para ser parte de ese futuro.
¿Tienes preguntas sobre LLMs o quieres profundizar en algún tema específico? No dudes en contactarme. La inteligencia artificial es fascinante, y hay mucho más por explorar.